How to Build AI-Friendly Site Architecture: GEO Optimization Checklist for 2026
How to Build AI-Friendly Site Architecture: GEO Optimization Checklist for 2026
Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. Pages with well-implemented structured data show 36% higher likelihood of appearing in AI-generated summaries. Your site architecture determines whether AI systems can access, understand, and cite your content at all.
GEO optimization has become essential as AI-powered search engines and generative tools reshape how users discover content. Traditional SEO strategies alone no longer guarantee visibility when ChatGPT, Perplexity, and Google's AI Overviews dominate search experiences. Websites need architecture that serves both traditional crawlers and AI systems simultaneously. This guide covers the complete framework for building AI-friendly site structure, specifically addressing SEO, AEO, and Generative Engine Optimization through flat hierarchies, schema implementation, topic clusters, and technical configurations that maximize your AI visibility across all platforms in 2026.
What Makes Site Architecture AI-Friendly in 2026?
How Do AI Crawlers Process Website Structure?
AI crawlers operate fundamentally differently from traditional search bots. Instead of simply cataloging URLs and indexing keywords, these systems attempt to reconstruct meaning through structural interpretation. They analyze how categories organize, how products relate to parent topics, and whether content can be summarized or compared across contexts. This shift means crawlers evaluate websites more like humans would, seeking to understand intent, hierarchy, and semantic relationships rather than merely discovering pages.
The interpretation process relies on stable structural signals. AI systems parse HTML hierarchy to separate concepts, identify topic relationships, and assign contextual meaning through clear boundaries between sections. When layouts use irregular formatting or semantically empty elements, crawlers fail to interpret relationships between concepts. Accordingly, pages with predictable hierarchy and consistent semantic markers achieve higher clarity because AI systems can align content meaning with stable markup patterns.
JavaScript rendering presents a critical limitation. OpenAI's GPTBot and Anthropic's ClaudeBot can retrieve JavaScript files but cannot execute them. ChatGPT places heavy emphasis on HTML content, accounting for 57.70% of its total fetch requests [1]. Because client-side rendered content only appears after JavaScript executes, it remains invisible to most AI parsers. Sites that rely on frameworks like React or Vue without server-side rendering often present empty containers to AI crawlers, making their content essentially non-existent for generative systems.
What Is the Tri-Modal Optimization Framework: SEO, AEO, and GEO?
The search landscape now requires simultaneous optimization across three distinct layers. SEO focuses on ranking in traditional search engine results pages. AEO structures content to be surfaced as direct answers in AI Overviews and voice assistants. GEO ensures content can be understood, cited, and incorporated into responses of generative AI systems and LLMs [2].
These strategies function as complementary layers rather than competing approaches. Traditional SEO establishes baseline visibility, with 76% of all URLs cited by AI platforms concurrently ranking in the top 10 of Google's traditional search results [3]. Nearly 40% of Google's AI Overviews rank in the top 10 organic search results, and nearly 70% rank in the top 100 [4]. AEO builds on this foundation by structuring content for zero-click searches and featured snippets. GEO extends reach by positioning content as trusted reference material for generative outputs.
Why Does Traditional Site Architecture Fail AI Systems?
Enterprise AI implementations reveal a fundamental architectural problem. Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. MIT NANDA Initiative findings indicate that up to 95% of enterprise generative AI projects fail to deliver ROI [5]. The core issue is not model sophistication but how systems handle context and integration into workflows.
Traditional architectures create fragmentation that AI cannot navigate. Systems encounter disconnected data, inconsistent definitions, and policies that vary across regions. The context gap emerges when AI can retrieve information without understanding constraints, approval states, or operational boundaries. A system might pull revenue figures without knowing whether they're provisional or finalized, or generate recommendations that violate policy [5]. This separation between data access and contextual understanding prevents AI from operating reliably within real enterprise environments, causing promising pilot results to fail at scale.
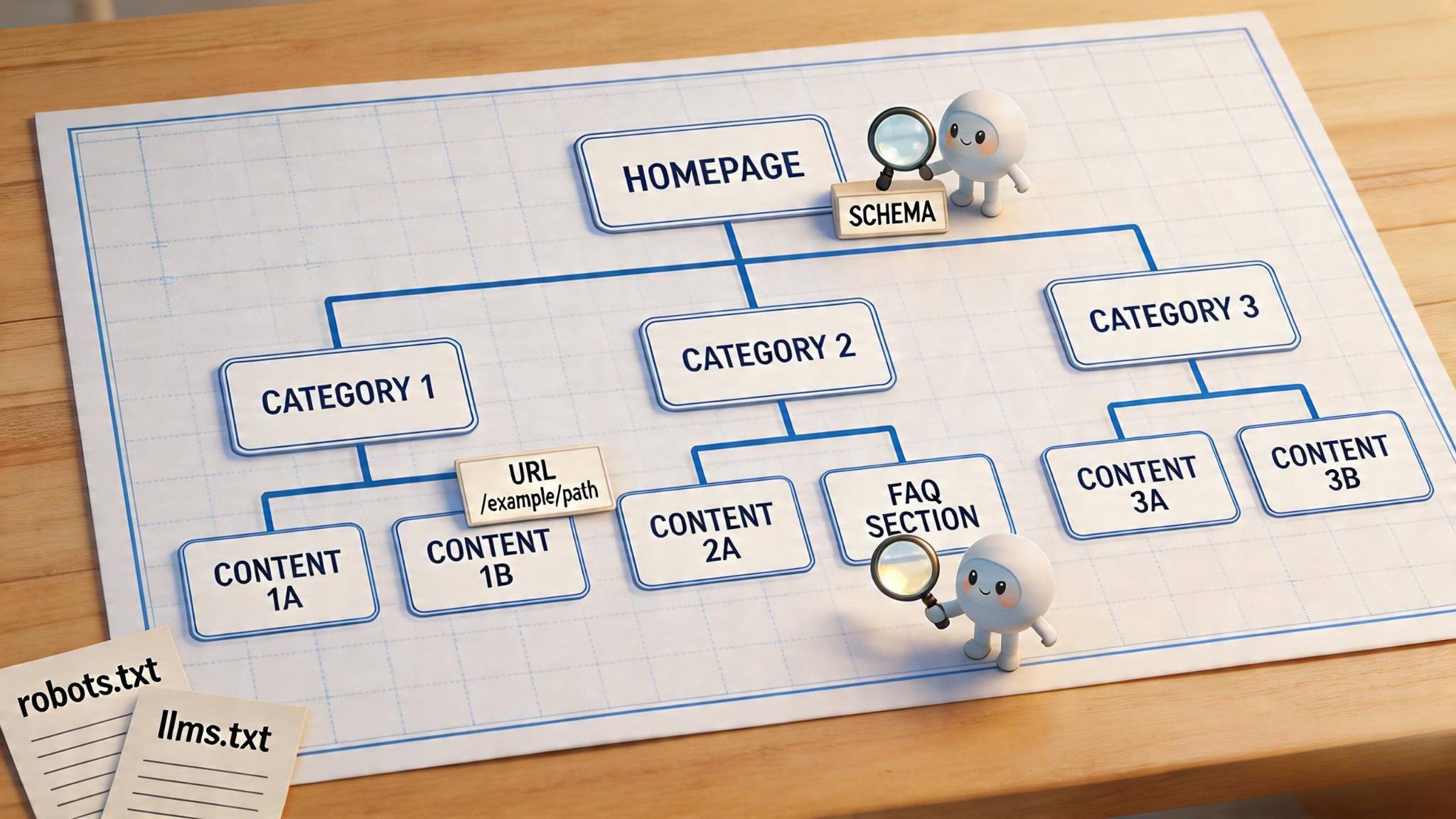
How Do You Build a Flat URL Hierarchy for AI Crawling?
Crawl efficiency starts with accessibility. Search engines allocate limited crawl budgets per site, making shallow structures critical for ensuring important pages get discovered and indexed [6]. Pages buried under multiple layers often receive minimal weight, even when indexed, because they accumulate fewer internal links and appear less important to ranking algorithms [7].
Does the 3-Click Rule Still Matter for Crawl Efficiency?
While research has debunked the strict 3-click rule as a guarantee of user satisfaction [8], the principle remains valuable for crawl optimization. Users continue clicking when they feel progress toward their goal [9]. For AI systems, however, proximity to the homepage directly influences crawl priority and indexing speed. Pages closest to the homepage receive higher crawl priority and are indexed faster [7].
Set click depth goals that keep key pages within two to three clicks from the homepage [6]. This flat architecture reduces crawl depth, allowing search bots to reach and index more pages within their crawl limits. For large sites, hierarchical structures can benefit crawling when they enable search engines to treat different sections distinctively, such as crawling news sections faster than archives [10].
What Are the Best Practices for Semantic URL Structure?
Semantic URLs provide context before users click. A URL like example.com/best-organic-coffee-beans immediately signals page content, while example.com/product/12345 offers no interpretive value. Search engines examine URLs for keywords, making semantic structure advantageous for indexing and ranking [1].
Structure URLs with descriptive keywords separated by hyphens rather than underscores. Google treats hyphens as word separators but reads underscores as single terms [1]. Keep URLs lowercase to avoid duplicate content issues, since example.com/Page and example.com/page may be treated as separate URLs [11]. Limit hierarchy to three levels maximum for optimal crawlability [12].
How Do Deep Nesting and Subdomains Hurt AI Visibility?
Pages with nesting levels beyond three should only appear in large ecommerce platforms [13]. Search engines treat subdomains as separate websites, requiring independent backlink profiles and keyword rankings. Each subdomain must be crawled and indexed separately, and subdomains don't pass link juice to the main domain [2]. Avoid subdomains unless content serves distinctly different functions or audiences.
How Do 301 Redirects Preserve Link Equity During Restructuring?
Implement 301 redirects from old URLs to new URLs during restructuring. A 301 redirect passes nearly all original page link equity to the new URL. Update all internal links to point directly to new URLs, avoiding redirect chains that dilute authority and slow page speed [4]. Redirect chains reduce link equity by approximately 15% per redirect [15]. Monitor for 404 errors using Google Search Console after implementation [14].
How Do Topic Clusters and Content Silos Boost AI Authority?
Topic clusters organize content into interconnected networks that signal expertise to both search engines and AI systems. This architecture mirrors how people naturally research subjects, starting with broad concepts and progressing into specific subtopics.
How Do Pillar Pages Build Topical Authority?
Pillar pages serve as comprehensive guides covering broad topics in depth. These pages provide overviews without diving into granular details, linking instead to cluster content that explores specific aspects. A pillar addressing "email marketing" might cover strategy, tools, and metrics at a high level, while cluster pages examine deliverability troubleshooting, automation workflows, and A/B testing frameworks individually.
Pillar content should span 2,000-4,000 words with clear H2/H3 hierarchies for navigation. Include clickable tables of contents that allow users to jump between sections. Optimize for short-tail keywords while ensuring each pillar links clearly to every supporting cluster page. This structure builds topical authority by demonstrating comprehensive coverage rather than fragmented articles competing for similar queries.
How Does Internal Linking Connect Cluster Content?
Internal links function as the connective tissue between pillar and cluster content. Every cluster page must link back to its pillar, typically within the first paragraph, signaling to search engines that content exists within a broader topic framework. Simultaneously, pillar pages should link out to all cluster content using contextually relevant placement within body text.
Cluster pages should also link to related clusters when semantically appropriate. For instance, a page discussing "email segmentation" naturally connects to content about "personalization tactics" within the same marketing automation cluster. This creates network effects that distribute link equity throughout the cluster while providing logical navigation paths for users.
Why Does Semantic Anchor Text Matter for AI Context?
Anchor text provides critical context signals for AI interpretation. Descriptive phrases like "customer retention strategies" outperform generic links such as "click here" or "learn more" because they explicitly communicate destination content. Vary anchor text naturally using synonyms and related phrases rather than exact-match repetition, which triggers spam filters.
Context surrounding anchor text matters equally. Google's BERT update enabled algorithms to understand link meaning based on nearby sentences and passages. Place links within relevant paragraphs where the surrounding text reinforces the relationship between source and destination pages.
How Does Entity Mapping Strengthen Your Content Hub?
Content Knowledge Graphs represent structured networks of entities within your website and their relationships to external authoritative sources. Entity linking connects your content's people, products, services, and concepts to Wikipedia, Wikidata, and Google's Knowledge Graph, disambiguating meaning for AI systems. This semantic structure helps AI platforms understand, interpret, and cite your content accurately across generative responses. Schema markup makes these entity relationships explicit, translating your content organization into machine-readable formats that AI systems prioritize when selecting sources for citations and answers.
How Should You Implement Schema Markup and Structured Data?
Schema markup transforms unstructured web content into machine-readable data that AI systems parse with precision. By explicitly defining what content represents rather than forcing algorithms to infer meaning, structured data directly influences how generative engines understand, extract, and cite information.
Which Schema Types Are Essential: Organization, Article, or FAQ?
Organization schema establishes entity authority by connecting your brand to external knowledge sources. The sameAs property links your website to LinkedIn, Wikipedia, and Wikidata profiles, helping AI systems disambiguate your entity and verify expertise [16]. Article schema provides publication dates, author credentials, and publisher details that AI platforms use to assess content credibility when selecting citation sources [17].
FAQPage schema delivers the highest citation probability among all schema types because it pre-structures content as question-answer pairs that AI can extract and present without additional processing. Pages with well-implemented structured data show 36% higher likelihood of appearing in AI-generated summaries compared to pages without schema [16].
How Does Stacking Multiple Schema Markups Achieve 3.1x Citation Rates?
Nesting structured data types within a single JSON-LD block helps Google understand page focus more clearly [18]. Rather than implementing separate schema scripts, combining related types signals primary content purpose. For example, an article about services can nest Person schema within the author property, creating entity relationships that increase AI citation probability [16]. Sites implementing comprehensive entity schema combined with accurate content-type schema see measurable AI Mode citation improvements over 30-60 day windows following deployment [3].
Why Does Breadcrumb Navigation Need BreadcrumbList Schema?
BreadcrumbList schema enables Google to display site hierarchy directly in search results instead of raw URLs [19]. This structured navigation helps AI systems understand content context within broader site architecture. Each ListItem requires a position integer and item URL, building from homepage (position 1) to current page [20].
What Product and Service Schema Do E-commerce Sites Need?
Product schema requires name and offers properties (price, priceCurrency) for rich result eligibility [21]. Service schema uses provider, areaServed, and serviceOutput properties to explicitly define business offerings for AI interpretation. Multi-typing items as both Product and Service allows sites to leverage properties from both types while qualifying for Product rich results [22].
How Do You Test and Validate Your Schema Implementation?
Google's Rich Results Test validates syntax and rich result eligibility, while Schema.org's validator checks comprehensive property completeness [23]. Monitor Google Search Console's Enhancements section for detected schema, error counts, and impression tracking over time [24]. Schema data must match visible page content exactly, as AI systems cross-reference structured data against on-page information to verify accuracy [16].
What Technical Infrastructure Do AI Bots Require?
Technical infrastructure determines whether AI systems can access, process, and cite your content at all. At the present time, configuration errors in foundational files block even perfectly optimized pages from generative platforms.
How Should You Configure robots.txt for AI Crawler Access?
The robots.txt file manages crawler permissions through user-agent directives. AI crawlers include GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended, and Perplexity's bot. To allow AI access, avoid blocking these agents in your robots.txt file. To prevent AI training on your content while maintaining citation eligibility, block training-specific crawlers like ClaudeBot while allowing query-time agents like Claude-User. This granular approach prevents content from being ingested into training datasets while preserving visibility in AI-generated responses. Remember that robots.txt operates as a voluntary protocol; compliant bots honor directives, but enforcement remains limited.
What Is llms.txt and How Do You Implement It?
Over 844,000 websites have implemented llms.txt files to guide AI systems toward high-value content [5]. Place this Markdown-formatted file at yourdomain.com/llms.txt with your site name as H1, a brief description in blockquote format, and H2 sections organizing key pages with descriptions. This curated structure helps AI navigate documentation, APIs, and guides without parsing entire sites during real-time query responses.
How Do Core Web Vitals Affect AI Crawling?
AI crawlers abandon slow pages faster than human visitors. Sites meeting all three Core Web Vitals thresholds see 24% fewer page abandonment rates [25]. Target Largest Contentful Paint under 2.5 seconds, Interaction to Next Paint under 200 milliseconds, and Cumulative Layout Shift under 0.1 [26]. These metrics directly influence crawl completeness and citation frequency.
Why Is JavaScript Rendering Critical for AI Accessibility?
Most AI crawlers cannot execute JavaScript. GPTBot, ClaudeBot, and PerplexityBot rely exclusively on server-rendered HTML [27]. Client-side rendered applications appear blank to these systems. Implement server-side rendering through Next.js or Nuxt.js, or use static site generation to ensure content exists in initial HTML responses before JavaScript execution.
How Do XML Sitemaps Support AI Content Discovery?
Submit XML sitemaps containing up to 50,000 URLs per file through Google Search Console and Bing Webmaster Tools [28]. Include lastmod tags with accurate timestamps to signal content freshness. Update sitemaps when publishing or modifying pages, helping AI systems prioritize recently updated content for citation consideration.
How Do You Measure and Monitor AI Visibility Performance?
How Do You Track Citation Frequency Across AI Platforms?
Citation tracking distinguishes between brand mentions and formal citations. A brand mention occurs when AI tools reference your brand in response text, while citations explicitly link to your website as a source. The mention-citation gap reveals critical content deficiencies: if AI knows your brand but never cites your content, competitors claim your authority [29]. Run queries across ChatGPT, Perplexity, Claude, and Google AI Overviews using target keywords, documenting whether your brand appears and in what position. Aim for 30%+ citation frequency for core category queries; top performers achieve 50%+ [30].
What Is AI Share of Voice and How Do You Monitor It?
AI Share of Voice measures your brand's percentage of total citations compared to competitors. Calculate by dividing your mentions by total brand mentions across identical prompts [31]. HubSpot now prioritizes being cited in LLMs more than any other CRM as a core business goal. In competitive categories, target AI SOV exceeding traditional market share by 10-20% [30].
How Do You Use Google Analytics 4 to Track AI-Referred Traffic?
AI referral traffic converts at rates 2-3x higher than traditional organic [30]. In GA4, create custom channel groups separating AI referrers (chatgpt.com, perplexity.ai, claude.ai) from standard referrals [32]. Use regex patterns to capture all AI traffic sources [33]. AI-referred sessions show 3-5x higher engagement rates and convert at 10%+ in B2B contexts [34].
How Should You Iterate Based on AI Citation Patterns?
Track platform-specific performance separately, as each AI system uses different citation mechanisms. Monitor weekly rather than monthly in high-competition industries [36]. Correlate citation improvements with content updates and schema deployments to identify effective GEO strategies [35].
Conclusion
AI-powered search has fundamentally changed how content gets discovered and cited. This framework addresses the complete optimization spectrum through flat URL hierarchies that maximize crawl efficiency, topic clusters that establish topical authority, comprehensive schema markup that delivers machine-readable context, and technical configurations that ensure AI accessibility.
Start by auditing your current site depth and eliminating pages buried beyond three clicks. Implement Organization, Article, and FAQPage schema on your highest-value pages. Configure robots.txt and llms.txt to guide AI crawlers toward your best content. Set up GA4 custom channel groups to track AI referral traffic separately.
The tri-modal approach matters because traditional SEO alone cannot capture generative platform visibility. By simultaneously optimizing for SEO, AEO, and GEO, your site architecture becomes accessible to both conventional crawlers and AI systems. You position your content as the authoritative reference material that ChatGPT, Perplexity, and Google's AI Overviews cite when answering user queries in 2026.
FAQs
Q1. What is AI-friendly site architecture and why does it matter in 2026?
AI-friendly site architecture is a website structure designed for both traditional search crawlers and AI systems like ChatGPT, Perplexity, and Google AI Overviews. It uses flat URL hierarchies, semantic markup, and server-rendered HTML so AI crawlers can access, understand, and cite your content. Pages with well-implemented structured data show 36% higher likelihood of appearing in AI-generated summaries, making this architecture critical for visibility in 2026.
Q2. How deep should my site's URL hierarchy be for optimal AI crawling?
Keep key pages within two to three clicks from the homepage. Search engines allocate limited crawl budgets per site, and pages closest to the homepage receive higher crawl priority and are indexed faster. Pages with nesting levels beyond three should only appear in large ecommerce platforms. Limit URL hierarchy to three levels maximum for optimal crawlability.
Q3. Which schema markup types have the biggest impact on AI citations?
FAQPage schema delivers the highest citation probability because it pre-structures content as question-answer pairs that AI can extract directly. Organization schema with sameAs properties establishes entity authority, and Article schema provides publication dates and author credentials for credibility assessment. Sites stacking multiple schema types in a single JSON-LD block see measurable citation improvements over 30-60 day windows.
Q4. Do AI crawlers execute JavaScript on my website?
No. Most AI crawlers including GPTBot, ClaudeBot, and PerplexityBot cannot execute JavaScript and rely exclusively on server-rendered HTML. Client-side rendered applications built with frameworks like React or Vue appear blank to these systems. Implement server-side rendering through Next.js or Nuxt.js, or use static site generation to ensure content exists in initial HTML responses.
Q5. How do I measure whether my site architecture improvements are working for AI visibility?
Track three metrics: citation frequency across AI platforms (aim for 30%+ on core queries), AI Share of Voice compared to competitors, and AI referral traffic in GA4 using custom channel groups for chatgpt.com, perplexity.ai, and claude.ai. AI-referred sessions convert at rates 2-3x higher than traditional organic traffic. Monitor weekly in competitive industries and correlate improvements with specific architecture changes.
References
[2] - https://rush-analytics.com/blog/subdomain-seo
[3] - https://www.digitalapplied.com/blog/schema-markup-after-march-2026-structured-data-strategies
[4] - https://www.magnatechnology.com/blog/301-redirects-how-to-use-them-and-their-seo-impact/
[5] - https://getpublii.com/blog/llms-txt-complete-guide.html
[6] - https://designindc.com/blog/why-flat-site-structures-outperform-deep-navigation-for-seo/
[7] - https://seomind.biz/seo-en/what-is-page-nesting-depth/
[8] - https://www.nngroup.com/articles/3-click-rule/
[9] - https://granicus.com/blog/website-myth-2-the-three-click-rule/
[10] - https://www.seroundtable.com/google-hierarchical-site-url-structures-36579.html
[11] - https://www.vazoola.com/resources/url-structure-in-seo
[12] - https://www.netranks.ai/blog/the-semantic-address-framework-url-structure-strategy-for-seo-and-geo
[13] - https://serpstat.com/blog/how-to-optimize-the-nesting-level-of-pages-on-the-website/
[15] - https://www.practicalecommerce.com/dos-and-donts-for-301-redirects
[16] - https://resollm.ai/blog/shema-markup-for-ai-search/
[17] - https://www.averi.ai/blog/schema-markup-for-ai-citations-the-technical-implementation-guide
[18] - https://pushleads.com/understanding-the-benefits-of-combining-structured-data/
[20] - https://developers.google.com/search/docs/appearance/structured-data/breadcrumb
[21] - https://nuxtseo.com/tools/schema-validator
[22] - https://www.schemaapp.com/schema-markup/services-schema-markup-schema-org-services/
[23] - https://developers.google.com/search/docs/appearance/structured-data
[24] - https://www.practicalecommerce.com/3-tools-to-build-validate-schema-markup
[25] - https://witscode.com/core-web-vitals-ai-crawlers-performance-optimization/
[26] - https://developers.google.com/search/docs/appearance/core-web-vitals
[27] - https://www.getpassionfruit.com/blog/javascript-rendering-and-ai-crawlers-can-llms-read-your-spa
[28] - https://yoast.com/what-is-an-xml-sitemap-and-why-should-you-have-one/
[29] - https://www.conductor.com/platform/features/ai-search-performance/ai-mention-citation-tracking/
[30] - https://www.averi.ai/how-to/how-to-track-ai-citations-and-measure-geo-success-the-2026-metrics-guide
[32] - https://www.analyticsmania.com/post/ai-traffic-in-google-analytics-4/
[33] - https://www.orbitmedia.com/blog/track-ai-traffic-ga4/
[34] - https://www.mo.agency/blog/how-to-track-ai-traffic-and-referrals-in-google-analytics-4
[35] - https://ayzeo.com/features/citation-analytics
[36] - https://siftly.ai/blog/tools-measure-citation-rates-ai-generated-content-brands-2026


